|
huntersx@sjtu.edu.cn Currently, I’m a fifth-year Ph.D. student in Cooperative Medianet Innovation Center at Shanghai Jiao Tong University (SJTU), supervised by Xi Zhou. Prior to that, I received my bachelor’s degree from Information Engineering at Xi’an Jiao Tong University (XJTU) in 2019. My research interests include but are not limited to Computer Vision, Natural Language Processing, and Cross-modal Learning . I am now focusing on Video Moment Retrieval (VMR), Referring Image Segmentation (RIS). I am also interested in Audio-Visual Video Parsing (AVVP), Vision and Language Tracking (VLT). Email / Google Scholar / GitHub / ORCID / Resumé |

|
|
|
- [2024.04] 🎉 One paper was accepted by SPL 2024.
- [2023.10] 🎉 One paper was accepted by Neurocomputing 2023.
- [2023.07] 🎉 One paper was accepted by ACM MM 2023.
- [2023.06] 🎉 One paper was accepted by ICANN 2023.
- [2023.02] 🎉 One paper was accepted by TCSVT 2023.
- [2022.05] 🎉 One paper was accepted by TCSVT 2022.
- [2022.03] 🎉 One paper was accepted by SIGIR 2022.
- [2021.09] 🎉 One paper was accepted by EMNLP 2021.
|
|
|
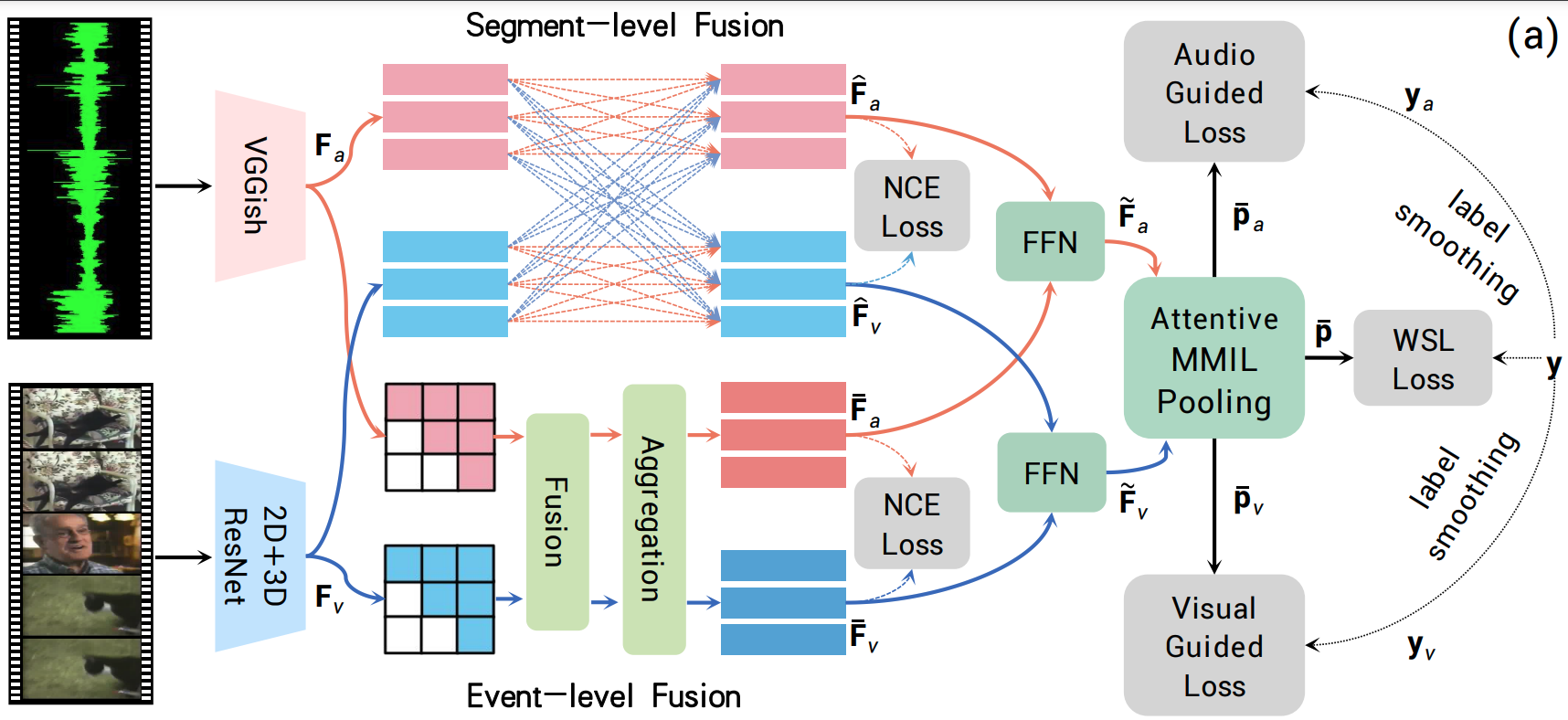
Xin Sun, Xuan Wang, Qiong Liu, Xi Zhou, paper in IEEE Signal Processing Letters (SPL), 2024. (CCF-C) DetailsIn this letter, we observe that previous studies often overlook the global context within video events. To alleviate this, we create a two-dimensional map to generate multi-scale event proposals for both audio and visual modalities. Subsequently, we fuse audio and visual signals at both segment and event levels with a novel boundary-aware feature aggregation method, enabling the simultaneous capture of local and global information. To enhance the temporal alignment between the two modalities, we employ segment-level and event-level contrastive learning. Our experiments consistently demonstrate the strength of our approach. |
|
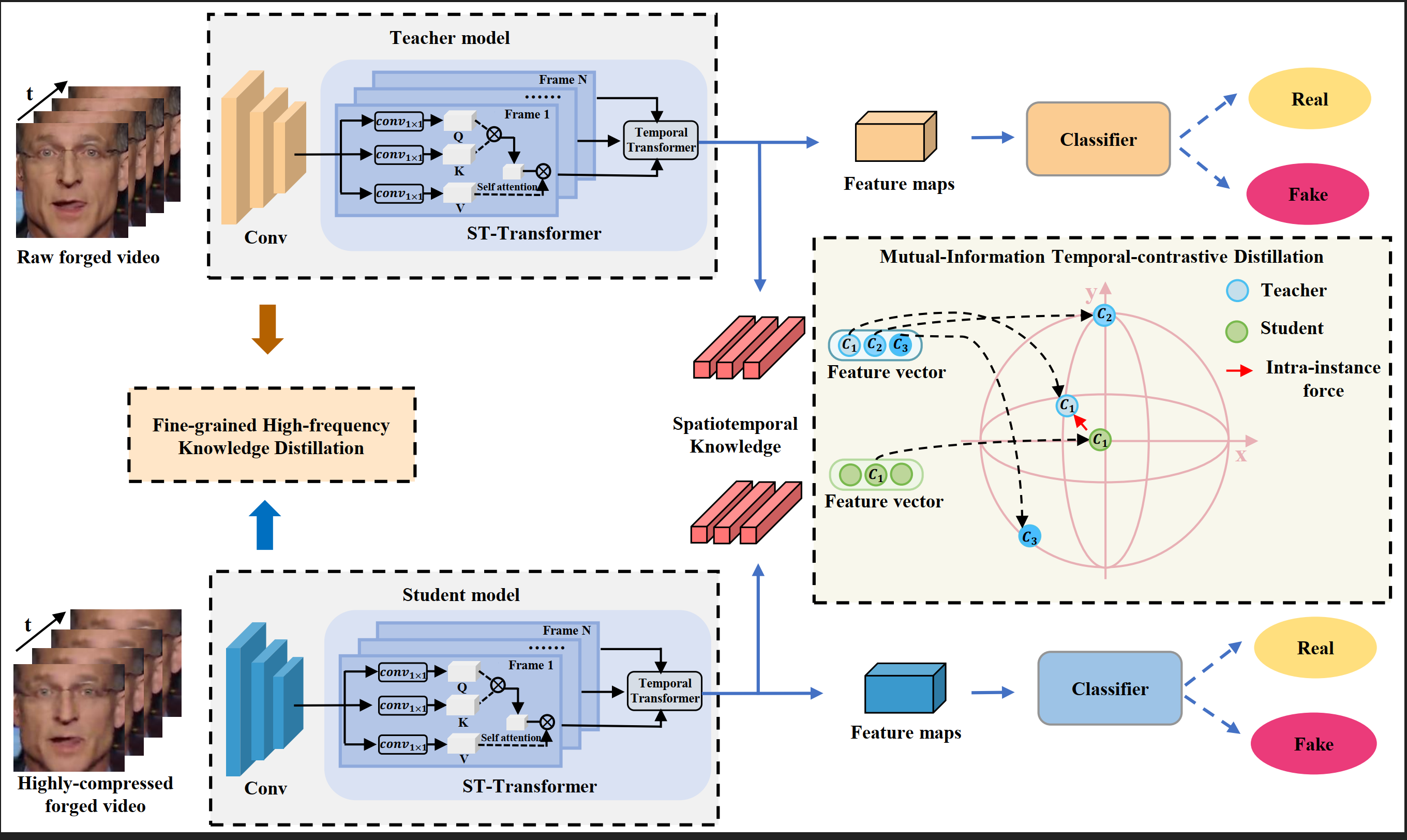
Yizhe Zhu, Chunuhi Zhang, Jialin Gao, Xin Sun, Zihan Rui, Xi Zhou, paper in Neurocomputing, 2023. (CCF-C) DetailsWe propose a Contrastive SpatioTemporal Distilling (CSTD) approach that leverages spatial-frequency cues and temporal-contrastive alignment to improve high-compressed deepfake video detection. Our approach employs a two-stage spatiotemporal video encoder to fully exploit spatiotemporal inconsistency information. A fine-grained spatial-frequency distillation module is used to retrieve invariant forgery cues in spatial and frequency domains. Additionally, a mutual-information temporal-contrastive distillation module is introduced to enhance the temporal correlated information and transfer the temporal structural knowledge from the teacher model to the student model. We demonstrate the effectiveness and robustness of our method on low-quality high-compressed deepfake videos on public benchmarks. |

|
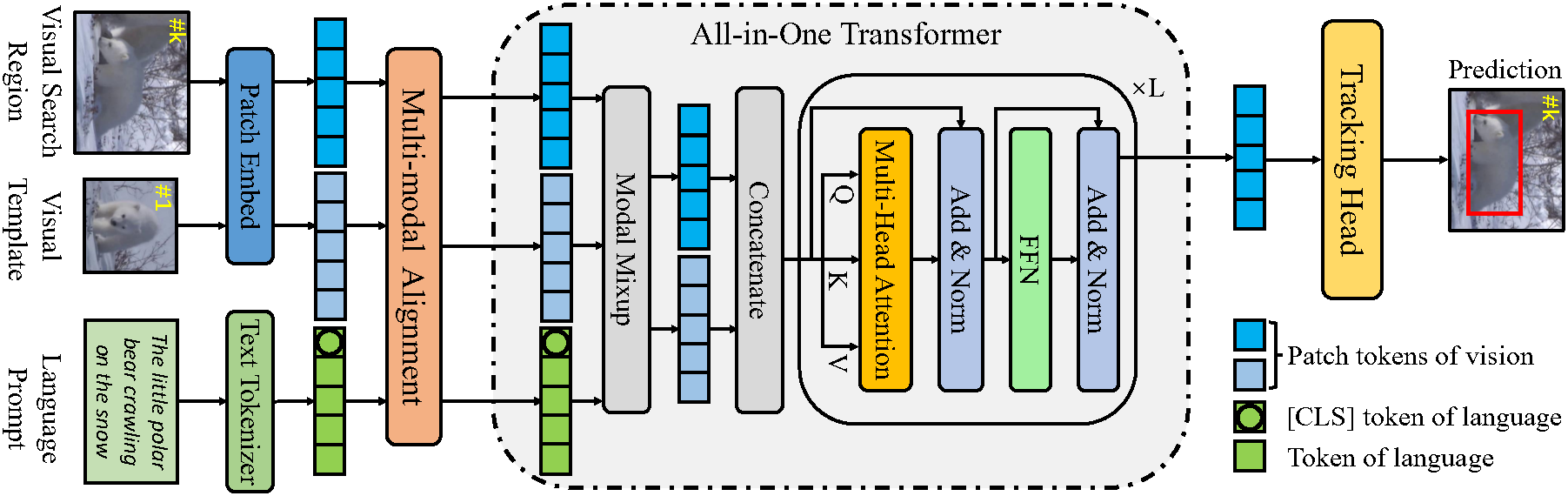
Chunuhi Zhang*, Xin Sun*, Li Liu, Yiqian Yang, Qiong Liu, Xi Zhou, Yanfeng Wang, (* means equal contribution) paper / code in ACM International Conference on Multimedia (ACM MM), 2023. (CCF-A) DetailsWe present a simple, compact and effective one-stream framework for VL tracking, namely All-in-One, which learns VL representations from raw visual and language signals end-to-end in a unified transformer backbone. The core insight is to is establish bidirectional information flow between well aligned visual and language signals as early as possible. We also develop a novel multi-modal alignment module incorporating cross-modal and intra-modal alignments to learn more reasonable VL representations. Extensive experiments on multiple VL tracking benchmarks have demonstrated the effectiveness and generalization of our approach. |
|
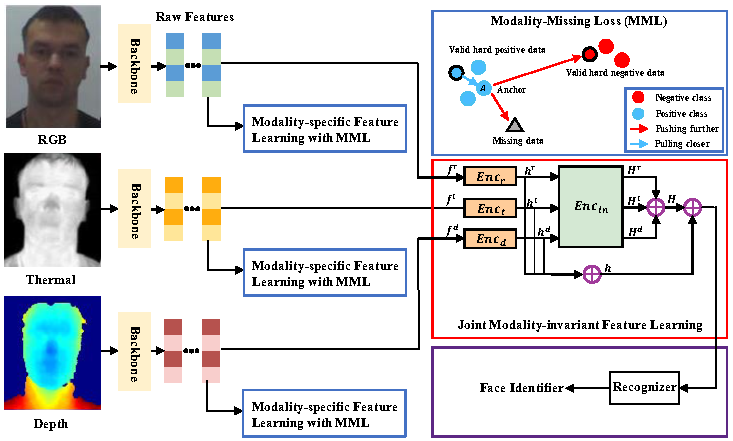
Yizhe Zhu, Xin Sun, Xi Zhou, paper in International Conference on Artificial Neural Networks (ICANN), 2023. (CCF-C) DetailsWe propose a multi-modal fusion framework that addresses the problem of uncertain missing modalities in face recognition. Specifically, we first introduce a novel modality-missing loss function based on triplet hard loss to learn individual features for RGB, depth, and thermal modalities. We then use a central moment discrepancy (CMD) based distance constraint training strategy to learn joint modality-invariant representations. This approach fully leverages the characteristics of heterogeneous modalities to mitigate the modality gap, resulting in robust multi-modal joint representations. |
|
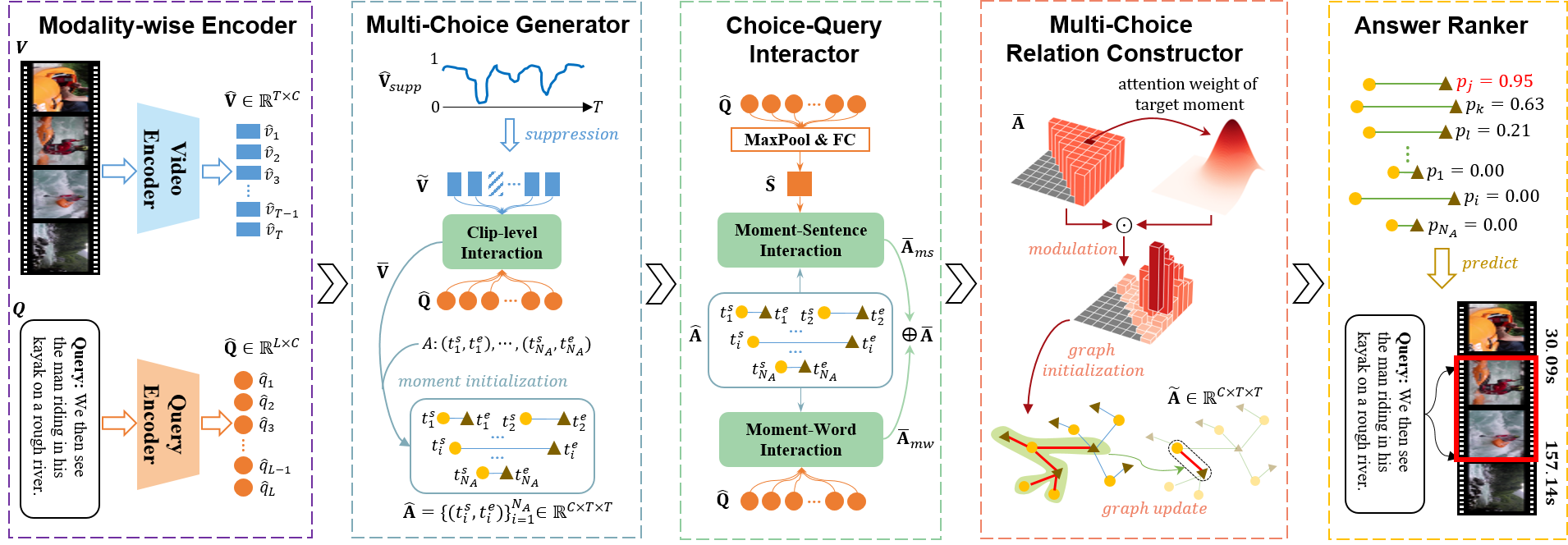
Xin Sun, Jialin Gao, Yizhe Zhu, Xuan Wang, Xi Zhou, paper in IEEE Transactions on Circuits and Systems for Video Technology (TCSVT), 2023. (CCF-B) DetailsThis manuscript is a substantial extension of our RaNet in EMNLP2021 with several improvements (i.e. background suppression module, clip-level interaction, and IoU attention mechanism). The background suppression module and IoU attention mechanism work together to enhance the hierarchical relations within the model by respectively modulating clip-level and moment-level features. The clip-level interaction provides a complementary perspective by capturing localized visual information, resulting in a multi-granular perception of inter-modality information. As a result, the harmonious integration of these modules significantly improves the model's ability to model comprehensive relations. |
|
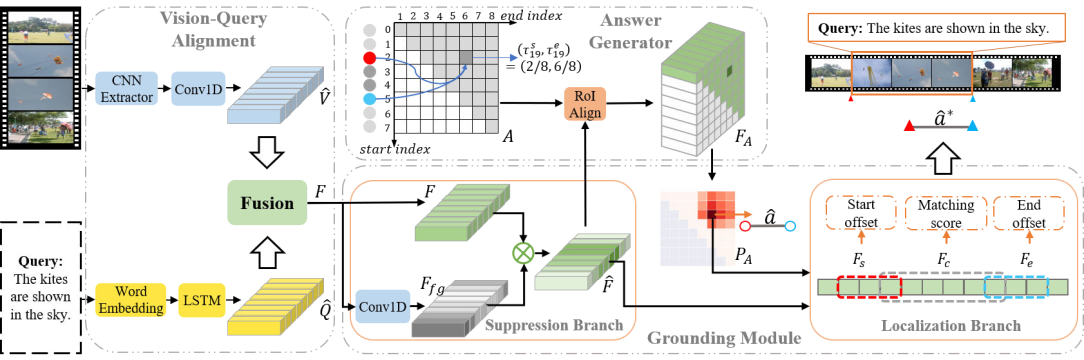
Jialin Gao, Xin Sun, Bernard Ghanem, Xi Zhou, Shiming Ge, paper in IEEE Transactions on Circuits and Systems for Video Technology (TCSVT), 2022. (CCF-B) DetailsWe present an efficient framework in a fashion from which to where to facilitate video grounding. The core idea is imitating the reading comprehension process to gradually narrow the decision space. The “which” step first roughly selects a candidate area by evaluating which video segment in the predefined set is closest to the ground truth, while the “where” step aims to precisely regress the temporal boundary of the selected video segment from the shrunk decision space. Extensive experiments demonstrate the effectiveness of our framework. |

|
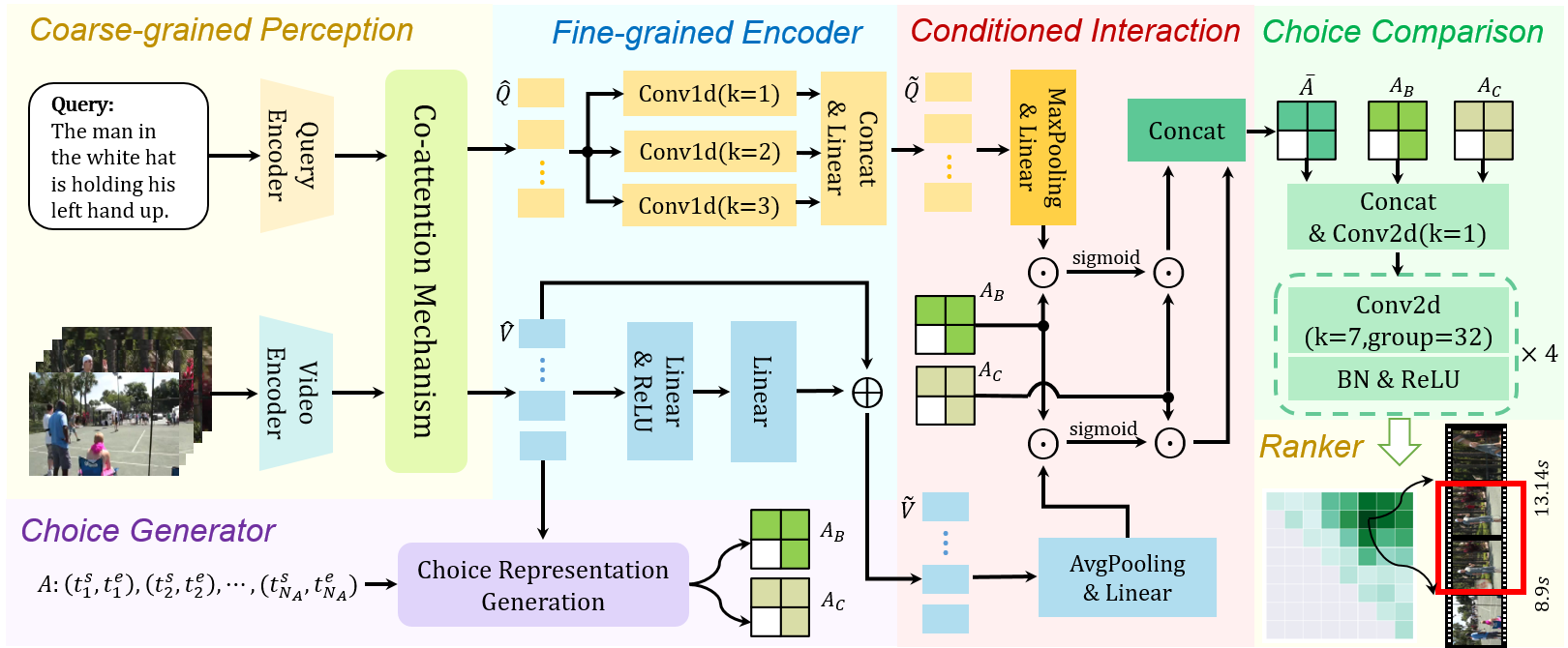
Xin Sun, Xuan Wang, Jialin Gao, Qiong Liu, Xi Zhou, paper / code in International ACM SIGIR Conference on Research and Development in Information Retrieval (SIGIR), 2022. (CCF-A) DetailsWe formulate moment retrieval task from the perspective of multi-choice reading comprehension and propose a novel Multi-Granularity Perception Network (MGPN) to tackle it. We integrate several human reading strategies (i.e. passage question reread, enhanced passage question alignment, choice comparison) into our framework and empower our model to perceive intra-modality and inter-modality information at a multi-granularity level. Extensive experiments demonstrate the effectiveness and efficiency of our proposed MGPN. |

|
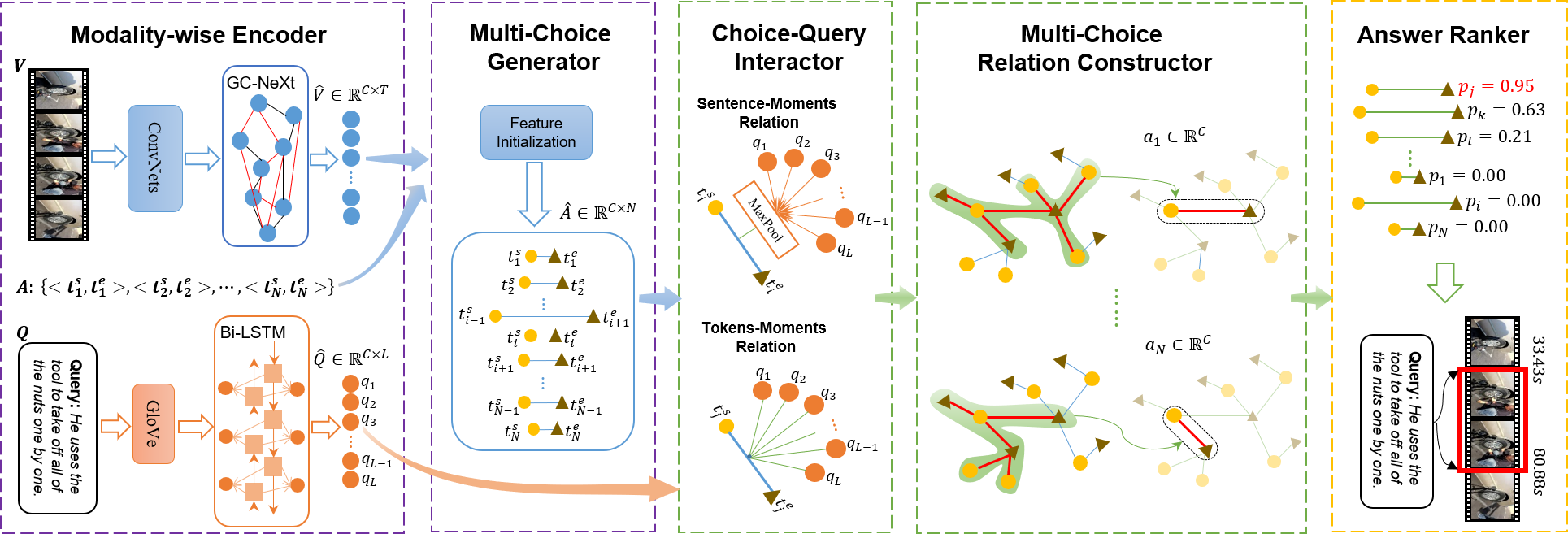
Jialin Gao*, Xin Sun*, MengMeng Xu, Xi Zhou, Bernard Ghanem, (* means equal contribution) paper / code in Conference on Empirical Methods in Natural Language Processing (EMNLP), 2021. (CCF-B) DetailsWe propose a novel Relation-aware Network (RaNet) to address the problem of temporal language grounding in videos. We propose to interact the visual and textual modalities in a coarse-and-fine fashion for token-aware and sentence-aware representation of each choice. Further, a GAT layer is introduced to mine the exhaustive relations between multi-choices for better ranking. Our model is efficient and outperforms the SOTA methods. |
|
|
-
[2023.02-2023.07] 🧑💻 Tiansuan Lab, AntGroup, Shanghai.
Referring Image Segmentation; Multi-Modal Large Language Model -
[2021.12-2022.02] 🧑💻 Multi-modal Perception Group, OPPO, Shanghai.
Vision Language Pre-training; Human Object Interaction -
[2020.07-2021.11] 🧑💻 Video Analysis Group, Cloudwalk, Shanghai.
Video Moment Retrieval; Action Recognition

|
|

|
|

|
|
|
|
-
[2019.09-Now] 🧑🎓 Shanghai Jiao Tong University (SJTU), Shanghai.
Ph.D. student in Information Engineering -
[2017.07-2017.08] 🧑🎓 The Hong Kong Polytechnic University (PolyU), Hong Kong.
Short-term Exchange -
[2015.08-2019.06] 🧑🎓 Xi'an Jiao Tong University (XJTU), Xi'an.
Bachelor of Engineering in Information Engineering

|
|

|
|

|
|
|
|
- [2022.11] 💰 Huawei Scholarship.
- [2020.05] 🏆 Regional Excellence Award in algorithm competition held by ZTE.
- [2018.10] 🏆 Outstanding Student Model Nomination in Xi'an Jiaotong University.
- [2018.10] 💰 Special Scholarship of Xi'an Jiaotong University (only 10 places).
- [2018.08] 🥇 First Place in National Undergraduate Electronic Design Contest.
- [2018.01] 🥇 First place in the VR training project held by Shanghai Jiaotong University.
- [2017.11] 🥈 Second Prize for the 11th Shaanxi College Students Mathematics Competition.
- [2017.10] 💰 National Endeavor Scholarship (top 5%).
- [2016.12] 🥇 First Prize for Shaanxi Division of the Undergraduate Group of the National University Students Mathematical Contest in Modeling.
- [2016.11] 🥇 First Prize for the 8th National College Student Mathematics Competition.
- [2016.10] 💰 PengKang Scholarship (top 5%).
- [2016.05] 🥉 Third Prize for Band C in 2016 National English Competition for College Students.
|
|
- Conference Reviewer: ACM MM'23
- Journal Reviewer: TCSVT